
Projects
How Machine Learning Streamlines the Occupational Coding Process for a Survey of Doctorate Recipients
2018 – 2020
Mathematica works with the National Center for Science and Engineering Statistics (NCSES) to automate its occupation coding process in the Survey of Doctorate Recipients (SDR) using advanced data-driven approaches and machine learning. This project aims to reduce the burden of manual review in the SDR and process the occupation coding timely and efficiently.
The NCSES currently relies on a labor-intensive review by trained coders to manually process more than 60 percent of occupation codes used in their survey. This process necessitated more than 2,800 coding-clerk hours for the 2015 and 2017 survey cycles combined. As the SDR captures new recipients of doctoral degrees in each survey cycle, the demand for manual review will continue to rise. NCSES sought a partner with machine learning capabilities that was familiar with their data who could explore new ways to automate occupation coding, reducing labor costs, and the potential for error.
SRI International
National Science Foundation
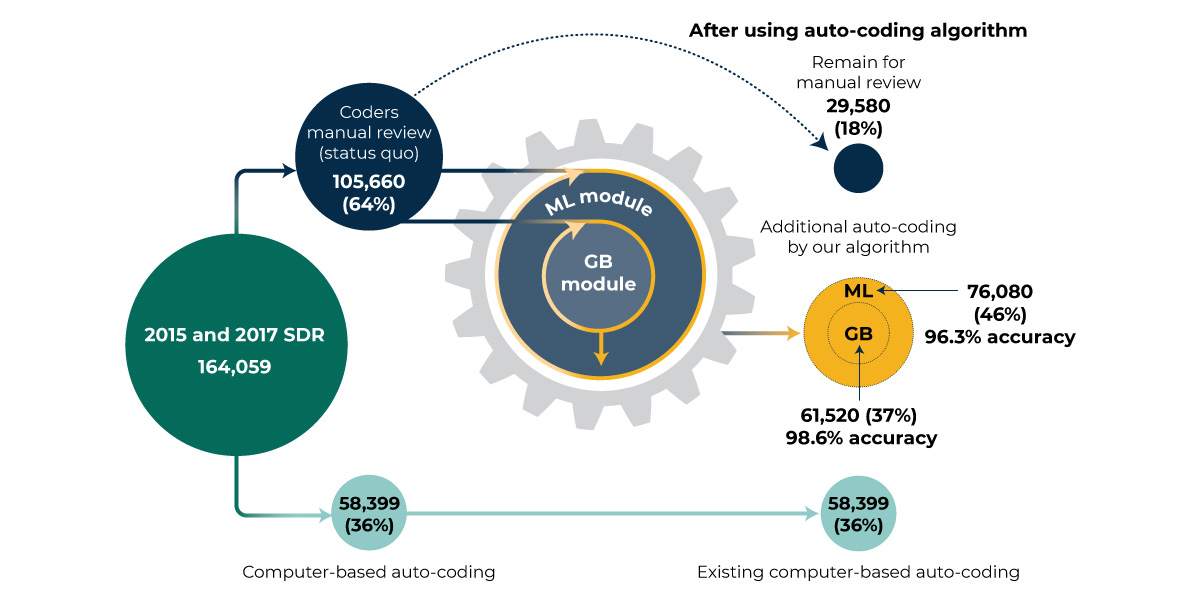
Mathematica developed an auto-coding algorithm that has coded more than 78% of previously manually-coded SDR records, and:
To solve their most pressing challenges, organizations turn to Mathematica for deeply integrated expertise. We bring together subject matter and policy experts, data scientists, methodologists, and technologists who work across topics and sectors to help our partners design, improve, and scale evidence-based solutions.
Work With Us
